本文基于JDK 1.8.0_211撰写,基于java.util.Arrays.sort()方法浅谈目前Java所用到的排序算法,仅个人见解和笔记,若有问题欢迎指证,着重介绍其中的TimSort排序,其源于Python,并于JDK1.7引入Java以替代原有的归并排序。
引入
Arrays.Sort方法所用的排序算法主要涉及以下三种:双轴快速排序(DualPivotQuicksort)、归并排序(MergeSort)、TimSort,也同时包含了一些非基于比较的排序算法:例如计数排序。其具体最终使用哪一种排序算法通常根据类型以及输入长度来动态抉择。
- 输入数组类型为基础类型时,采用双轴快速排序,辅以计数排序;
public static void sort(int[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);}- 输入数组类型为包装类型时,采用归并排序或TimSort(除非经过特殊的配置,否则默认采用TimSort)
public static void sort(Object[] a) { if (LegacyMergeSort.userRequested) legacyMergeSort(a); else ComparableTimSort.sort(a, 0, a.length, null, 0, 0);} public static <T> void sort(T[] a, Comparator<? super T> c) { if (c == null) { sort(a); } else { if (LegacyMergeSort.userRequested) legacyMergeSort(a, c); else TimSort.sort(a, 0, a.length, c, null, 0, 0); }} /** To be removed in a future release. */ private static <T> void legacyMergeSort(T[] a, Comparator<? super T> c) { T[] aux = a.clone(); if (c==null) mergeSort(aux, a, 0, a.length, 0); else mergeSort(aux, a, 0, a.length, 0, c); }排序稳定性
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i] = r[j],且 r[i] 在 r[j] 之前,而在排序后的序列中,r[i] 仍在 r[j] 之前,则称这种排序算法是稳定的;否则称为不稳定的。
稳定性的含义:如果我们需要在二次排序后保持原有排序的意义,就需要使用到稳定性的算法
例子:我们要对一组商品排序,商品存在两个属性:价格和销量。当我们按照价格从高到低排序后,要再按照销量对其排序,这时,如果要保证销量相同的商品仍保持价格从高到低的顺序,就必须使用稳定性算法。
快速排序与双轴快速排序
快速排序简介
单轴快速排序 即为我们最常见的一种快速排序方式,我们选取一个基准值(pivot),将待排序数组划分为两部分:大于pivot 和 小于pivot,再对这两部分进行单轴快速排序... 但是这种方式对于输入数组中有很多重复元素时效率不太理想。
单轴三取样切分快速排序 作为单轴快速排序的优化版本,其主要优化相同元素过多情况下的快排效率,同样选取一个基准值,但将待排序数组划分三部分: 大于pivot、等于pivot、大于pivot。
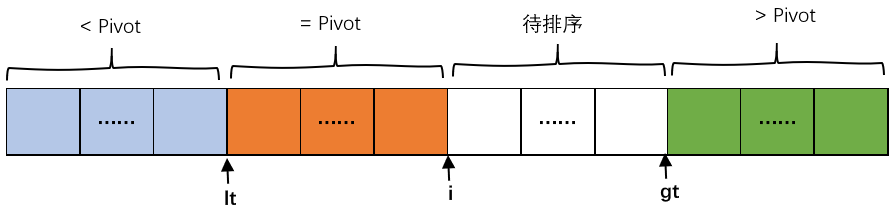
双轴快速排序 选取两个 基准值pivot1,pivot2,且保证pivot1<=pivot2,其具体实现与三取样切分类似,不过时将待排序数组划分以下三部分:小于pivot,介于pivot1与pivot2之间,大于pivot2。

DualPivotQuicksort实现优化
Java在实现DualPivotQuickSort时,并未盲目使用双轴快速排序,而是基于输入长度选取排序算法。
(1)针对int、long、float、double四种类型,跟据长度选取的排序算法如下:
- 当待排序数目小于47,采用插入排序
- 当待排序数目小于286,采用双轴快排
- 当待排序数目大于286,采用归并排序
我们暂且将其称之为一个标准的双轴快排
static void sort(int[] a, int left, int right, int[] work, int workBase, int workLen) { // Use Quicksort on small arrays if (right - left < QUICKSORT_THRESHOLD) { sort(a, left, right, true); return; } // Use MergingSort doMerge(); }private static void sort(int[] a, int left, int right, boolean leftmost) { // Use insertion sort on tiny arrays if (length < INSERTION_SORT_THRESHOLD) { doInertionSort(); } doDualPivotQuickSort();}
(2)针对short、char两种类型,根据长度选取的排序算法如下:
- 当待排序数目小于3200,采用标准双轴快排;
- 当待排序数目大于3200,采用计数排序(CountingSort)
(3)针对byte类型,根据长度选取的排序算法如下:
- 当待排序数目小于29,采用插入排序;
- 当待排序数目大于29,采用计数排序(CountingSort)
非基于比较排序算法-计数排序
计数排序与传统的基于比较的排序算法不同,其不通过比较来排序。我们常见的非基于比较的排序算法有三种:桶排序、计数排序(特殊桶排序)、基数排序,有兴趣的可以逐个去了解,这里主要讲解计数排序。
使用前提
使用计数排序待排序内容需要是一个有界的序列,且可用整数表示
引入
计数排序顾名思义即需要统计数组中的元素个数,通过另外一个数组的地址表示输入元素的值,数组的值表示元素个数。最后再将这个数组反向输出即可完成排序,见下方示例:
假设:一组范围在 0~10 之间的数字,9, 3, 5, 4, 9, 1, 2, 7, 8,1,3, 6, 5, 3, 4, 0, 10, 9, 7, 9
第一步:建立一个数组来统计每个元素出现的个数,因为是0~10,则建立如下数组 Count:

第二步:遍历输入数组,将获取到的内容放置到Count 数组对应的位置,使当前位置+1,例如当前为9:

以此类推,遍历完整个输入数组,则得到一个完整状态的Count:

这时候,Count中记录了输入数组所有的元素出现的次数,将Count数组按次数输出即可得到最终排序输出:
0, 1, 1, 2, 3, 3, 3, 4, 4, 5, 5, 6, 7, 7, 8, 9, 9, 9, 9, 10
计数排序的稳定性与最终实现
根据上面稳定性的定义,大家不难发现上面的实现过程不能保证基数排序的稳定性,而实际上计数排序是一个稳定的排序算法,下面我们通过上面那个例子来引出计数排序的最终实现。
例子:输入数组 [ 0,9,5,4,5 ],范围0 ~ 9
第一步:将Count数组中所记录的内容进行更改,由记录当前元素的出现的次数 修正为 记录当前索引出现的次数和当前索引之前所有元素次数的和,这样在索引中存储的值就是其真实的排序后排位数,例如9的值为5,则9的排序后的位置就是第5位:

第二步:我们从后向前遍历原序列,此时为5,则在最终排序序列的位置为4(索引为3)的地方放置5,并将Count序列的5索引处的值-1。
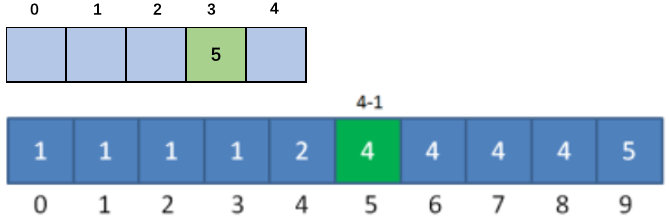
以此类推:到第二个5时,Count数组中的值为3(索引为2),这样就保证了插入排序的稳定性。
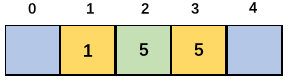
源码实现
/** The number of distinct byte values. */private static final int NUM_BYTE_VALUES = 1 << 8;static void sort(byte[] a, int left, int right) { int[] count = new int[NUM_BYTE_VALUES]; // 建立count数组 for (int i = left - 1; ++i <= right; count[a[i] - Byte.MIN_VALUE]++ ); // 从尾部开始遍历 for (int i = NUM_BYTE_VALUES, k = right + 1; k > left; ) {
while (count[--i] == 0); byte value = (byte) (i + Byte.MIN_VALUE); int s = count[i]; do { a[--k] = value; } while (--s > 0); } }TimSort
Timsort是工业级算法,其混用插入排序与归并排序,二分搜索等算法,亮点是充分利用待排序数据可能部分有序的事实,并且依据待排序数据内容动态改变排序策略——选择性进行归并以及galloping。另外TimSort是一个稳定的算法,其最好的执行情况要优于普通归并排序,最坏情况与归并排序相仿:

针对小数据优化
针对输入长度较短的数组排序,很多轻量级排序即可胜任,故TimSort在基于输入数组长度的条件下,做出如下优化:
当输入序列的长度小于基准值时,将采用插入排序直接对输入序列排序。基准值的选取:(1)Python:64(2)Java:32
此外上面提到的插入排序,Java的实现中,对这部分做了优化,严格来说这里使用的是二分插入排序。将插入排序与二分查找进行了结合。因为插入排序的索引左侧均是有序序列:
- 传统意义上需要单个依次向前比较,直到找到新插入元素放置的位置;
- 二分插入排序,则在此处采用二分查找来确认插入元素的放置位置。
TimSort简要流程
TimSort is a hybrid sorting algorithm that uses insertion sort and merge sort.
The algorithm reorders the input array from left to right by finding consecutive (disjoint) sorted segments (called "runs" from hereon). If the run is too short, it is extended using insertion sort. The lengths of the generated runs are added to an array named runLen. Whenever a new run is added to runLen, a method named mergeCollapse merges runs until the last 3 elements in runLen satisfy the following two conditions (the "invariant"):
- runLen [n-2] > runLen [n-1] + runLen [n]
- runLen [n-1] > runLen [n]
Here n is the index of the last run in runLen. The intention is that checking this invariant on the top 3 runs in runLen in fact guarantees that all runs satisfy it. At the very end, all runs are merged, yielding a sorted version of the input array.
TimSort算法通过找到连续的(不相交)排序的段(此后称为"Run"),如果Run过短,则使用插入排序扩充。生成的Run的长度被称添加到一个名为runLen数组中,每当将新Run添加到runLen时,名为mergeCollapse的方法就会尝试合并Run,直到runLen中的元素元素满足两个恒定的不等式。到最后,所有Run都将合并成一个Run,从而生成输入数组的排序版本。
基本概念 - Run
TimSort算法中,将有序子序列(升序序列和严格降序序列)称之为Run,例如如下将排序序列:1,2,3,4,5,4,3,6,8,10
则上面的序列所有的Run如下:1,2,3,4,5,5,3,2,2,6,8,10
TimSort中会区分其序列为升序还是降序,如果是降序会强行反转Run,使其成为升序,则上述的序列经过反转后即为:1,2,3,4,5,5,2,3,2,6,8,10
注意:Run必须是升序(可以相等)和严格降序(不能相等),严格降序的原因是保证TimSort稳定性,因为降序需要反转。
基本概念 - MinRun
当两个数组归并时,当这个数组Run的数目等于或略小于2的乘方时,效率最高(基本数学概念参考:listsort.txt)。
反过来说,我们需要得到一个Run的最小长度,使得其划分的Run的数目达到上述标准准,即:选取32-64(16-32)这个范围作为MinRun的范围,使得原排序数组可以被MinRun分割成N份,这个N等于或略小于2的乘方。
- 如果当前的Run长度小于MinRun:尝试把后面的元素通过插入排序放入Run中,以尽量达到MinRun的长度(剩余长度满足的情况下);
- 如果当前的Run长度大于MinRun:不处理。
通过上述的操作我们就收获了一系列Run,将其放置到堆栈runLen中,并尝试对其进行归并:
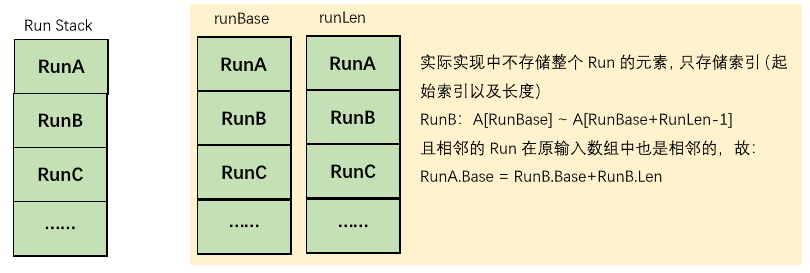
/** * A stack of pending runs yet to be merged. Run i starts at * address base[i] and extends for len[i] elements. It's always * true (so long as the indices are in bounds) that: * * runBase[i] + runLen[i] == runBase[i + 1] * * so we could cut the storage for this, but it's a minor amount, * and keeping all the info explicit simplifies the code. */ private int stackSize = 0; // Number of pending runs on stack private final int[] runBase; private final int[] runLen; /* * 初始化部分截取 * 分配runs-to-be-merged堆栈(不能扩大) */ int stackLen = (len < 120 ? 5 : len < 1542 ? 10 : len < 119151 ? 24 : 49); runBase = new int[stackLen]; runLen = new int[stackLen]; /** * Pushes the specified run onto the pending-run stack. * * @param runBase index of the first element in the run * @param runLen the number of elements in the run */ private void pushRun(int runBase, int runLen) { this.runBase[stackSize] = runBase; this.runLen[stackSize] = runLen; stackSize++; }归并原则 - 不等式
基于如下原因:
(1)堆栈runLen内存占用尽量减小,则其是线上具有固定大小,不考虑扩容(参考上述源码的注释);
(2)让归并的两个Run的数目都尽量接近,更接近普通归并的模式,提高归并效率。
TimSort在runLen上制定了两个不等式以使runLen尽量贴近上面的条件:
- Run[n-1] > Run[n] + Run[n+1]
- Run[n] > Run[n+1]
当目前runLen满足这两个不等式时,则不进行归并,否则进行归并,因为TimSort时稳定的排序算法,则仅允许归并相邻的两个Run:
- 如果不满足不等式一:归并Run[n]与Run[n-1]、Run[n+1]中长度较短的Run
- 如果不满足不等式二:归并Run[n]与Run[n+1]
不变式的含义:
不变式一:从右至左读取长度,则待处理的runLen的增长至少与斐波那契额增长的速度一样快,则更使得两个归并的Run的大小更为接近;
不变式二:待处理的runLen按递减顺序排序。
通过以上两个推论可以推测runLen中的Run数目永远会收敛于一个确定的数,以此证明了只用极小的runLen堆栈就可以排序很长的输入数组,也正是因为如此在实现上不考虑扩容问题,如果需要详细数学例证可以查看文后Reference。
实际代码是线上,Java、Python、Android保证不等式的手段是检查栈顶三个元素是否满足,即上述不等式的n取栈顶第二个,如果不满足则归并,归并完成后再继续检查栈顶三个直到满足为止。
/** * Examines the stack of runs waiting to be merged and merges adjacent runs * until the stack invariants are reestablished: * * 1. runLen[i - 3] > runLen[i - 2] + runLen[i - 1] * 2. runLen[i - 2] > runLen[i - 1] * * This method is called each time a new run is pushed onto the stack, * so the invariants are guaranteed to hold for i < stackSize upon * entry to the method. */ private void mergeCollapse() { while (stackSize > 1) { int n = stackSize - 2; if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) { if (runLen[n - 1] < runLen[n + 1]) n--; mergeAt(n); } else if (runLen[n] <= runLen[n + 1]) { mergeAt(n); } else { break; // Invariant is established } } }归并排序
归并优化一:内存优化
由于需要保证TimSort的稳定性,则归并排序不能采用原地排序,TimSort引入了临时数组来进行归并,并将参与归并的两个Run中较小的那个放置到临时数组中,以节省内存占用。同时区分从小开始归并和从大开始归并。
归并优化二:缩短归并Run长度
两个参与归并的Run,由很多部分其实时不用参与归并的(从Run的某个位置开始的前面或后面的元素均小于或大于另一个Run的全部元素,则这部分就可以不参与归并),加之归并两个Run是在原输入数组中是相邻,则我们考虑是否可以在去掉部分头尾元素,以达到缩短归并长度的目的:
(1)在RunA查找一个位置 I 可以正好放置RunB[0],则 I 之前的数据都不用参与归并,在原地不需要变化;
(2)在RunB查找一个位置 J 可以正好放置RunA[Len-1],则 J 之后的数据都不用参与归并,在原地不需要变化;
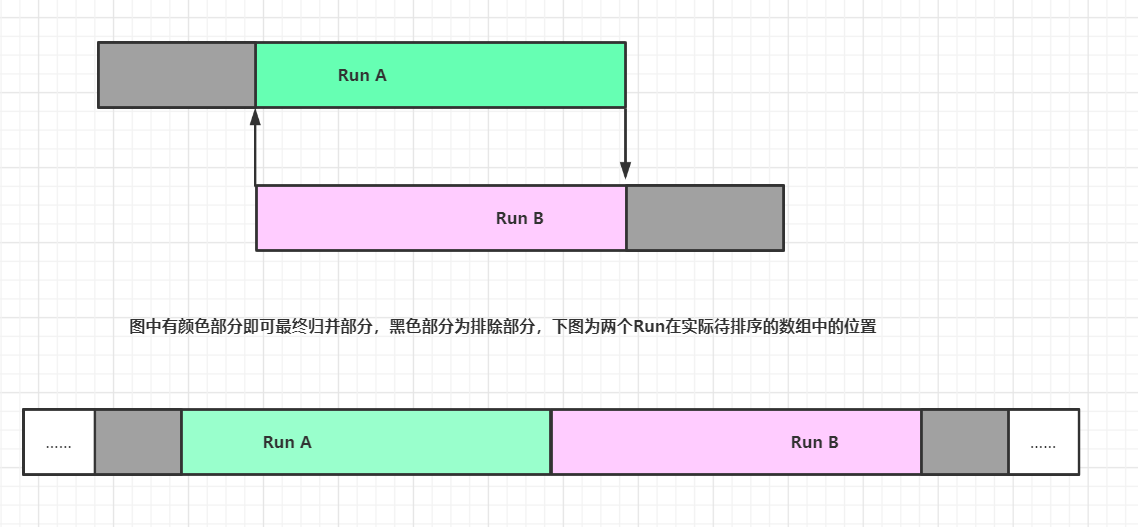
归并排序优化三:GallopingMode
在归并时有可能存在以下的极端情况:
RunA 的所有元素都小于RunB,如果这个情况下采用常规的归并效率肯定不理想
于是TimSort引入了GallopingMode,用来解决上述的问题,即当归并时,一个Run连续n的元素都小于另一个Run,则考虑是否有更多的元素都小于,则跳出正常归并,进入GallopingMode,当不满足Galloping条件时,再跳回到正常归并(不满足Galloping条件时强制使用Galloping效率低下)。如果RunA的许多元素都小于RunB,那么有可能RunA会继续拥有小于RunB的值(反之亦然),这个时候TimSort会跳出常规的归并排序进入Galloping Mode,这里规定了一个阈值MIN_GALLOP,默认值为7。

下面模拟一次Galloping,以mergeHi为例(从大开始归并):
(1)例如此时RunA已经连续赢得7次归并,而RunB的元素还没有一次被选取,则已经达到阈值,进入GallopingMode:

进入GallopingMode,说明此时已经有RunA已经小于RunB末尾的7个数字,TimSort猜测会有更多的RunA的数字小于RunB,则进行以下操作:
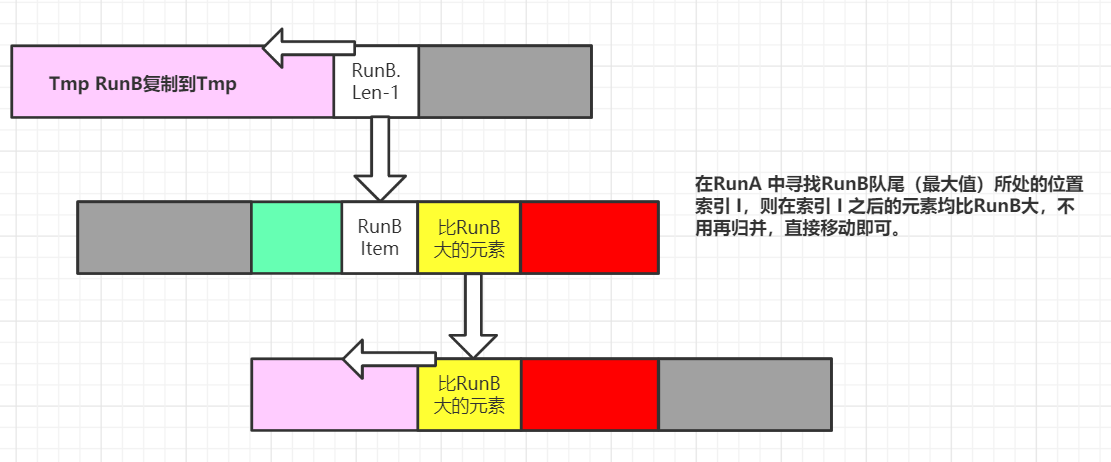
以上则完成了一次Galloping,在这一次Galloping中,我们一次性将所有大于RunB[len-1]的RunA元素一次性移动(包括RunB[len-1],放置到这次移动的RunA元素后),不需要再依次归并。
这时涉及到一个概念即是否继续执行Galloping,还是回到正常的归并?
我们判断这一次移动的元素个数是否还满足阈值(黄色),如果满足则继续,在RunA中寻找RunB[len-2]的位置,否则回到正常的归并。
Java版本实现中每次进入和退出Galloping会变更这个进入GallopingMode的阈值,应该是某种奖惩机制,这里不做说明。
TimSort 的实现缺陷
在Java8中TimSort的实现是有缺陷的,在极端复杂情况下可能会触发异常,其主要原因是如果只检查栈顶三个Run的不等式关系,没办法办证这个不等式在整个runLen堆栈上成立,参考以下示例:
不等式被破坏的代价,即为Run的归并时机被破坏,导致在某些极端情况下,会导致堆栈中的Run超过我们通过不等式推出来的那个收敛值导致溢出:ArrayOutOfBoundsException,这个Bug在后续版本已经修复:

提供的修复方案即为检查栈顶四个Run而非三个:
private void newMergeCollapse() { while (stackSize > 1) { int n = stackSize - 2; if ( (n >= 1 && runLen[n-1] <= runLen[n] + runLen[n+1]) || (n >= 2 && runLen[n-2] <= runLen[n] + runLen[n-1])) { if (runLen[n - 1] < runLen[n + 1]) n--; } else if (runLen[n] > runLen[n + 1]) { break; // Invariant is established } mergeAt(n); } }有兴趣手动Debug这个问题的读者可以参考如下Git操作:https://github.com/Rekent/java-timsort-bug
部分源码注释
入口方法:
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c, T[] work, int workBase, int workLen) { assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length; int nRemaining = hi - lo; if (nRemaining < 2) { return; // Arrays of size 0 and 1 are always sorted } // 如果小于32位,则不采用TimSort,而是采用二分插入排序对整个数组直接排序 if (nRemaining < MIN_MERGE) { // 获取第一个序列(Run) int initRunLen = countRunAndMakeAscending(a, lo, hi, c); // 二分插入排序(从第一个Run后开始向前排序,第一个Run已经是增序了,不用再排) binarySort(a, lo, hi, lo + initRunLen, c); return; } MyTimSort<T> ts = new MyTimSort<>(a, c, work, workBase, workLen); // 根据当前排序数组长度生成最小的Run长度 int minRun = minRunLength(nRemaining); do { // 识别下一个Run序列,返回这个Run的长度 int runLen = countRunAndMakeAscending(a, lo, hi, c); // 如果当前的Run序列长度小于MinRun长度,则尝试扩展到MinRun的长度(从后面选取元素进行二分拆入排序) if (runLen < minRun) { // 如果剩余长度小于当前的MinRun,则补全为剩余的长度 int force = nRemaining <= minRun ? nRemaining : minRun; binarySort(a, lo, lo + force, lo + runLen, c); runLen = force; } // 记录当前Run的起始Index以及Run长度 ts.pushRun(lo, runLen); // 尝试合并 ts.mergeCollapse(); // 开始下一轮的Run寻找 lo += runLen; nRemaining -= runLen; } while (nRemaining != 0); // 所有的Run都已经寻找完毕,必须合并所有Run assert lo == hi; ts.mergeForceCollapse(); assert ts.stackSize == 1; }归并方法(优化缩短归并长度):
/** * 合并i以及i+1两个Run. Run i 一定是倒数第二个或者倒数第三个Run * * @param i 合并堆栈的索引 */ private void mergeAt(int i) { // i 一定是倒数第二个或者倒数第三个,换句话说,i一定是stackSize-2或者stackSize-3 assert stackSize >= 2; assert i >= 0; assert i == stackSize - 2 || i == stackSize - 3; int base1 = runBase[i]; int len1 = runLen[i]; int base2 = runBase[i + 1]; int len2 = runLen[i + 1]; assert len1 > 0 && len2 > 0; assert base1 + len1 == base2; // 将i的长度更新len1+len2,即合并后的长度,如果是倒数第三个Run,则将倒数第一个长度合并到倒数第二个Run中(倒数第二个和倒数第三个Run合并了) // [RUN1,RUN2,RUN3] -> [RUN1+RUN2,RUN3] ; [RUN1,RUN2] -> [RUN1+RUN2] runLen[i] = len1 + len2; if (i == stackSize - 3) { runBase[i + 1] = runBase[i + 2]; runLen[i + 1] = runLen[i + 2]; } stackSize--; // 缩短归并长度:在Run1中寻找Run2的起始节点位置(Run2的首个元素应该放置Run1中的位置),可以忽略run1中先前的元素(因为其已经有序) int k = gallopRight(a[base2], a, base1, len1, 0, c); assert k >= 0; // !!! Run1 这个位置之前的可以省略不再排序,因为Run2所有元素都大于这个位置 base1 += k; len1 -= k; // 如果剩余排序长度为0,则已经有序,不用再排序(Run1全体大于Run2) if (len1 == 0) { return; } // 缩短归并长度:在Run2中寻找Run1的最后一个元素应该放置的位置,!!! Run2的这个位置后面可以省略不再排序,因为后面所有元素都大于Run1 len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c); assert len2 >= 0; // 如果剩余排序长度为0,则已经有序,不用再排序(Run2全体大于Run1) if (len2 == 0) { return; } // 并归两侧,选取较短的一方作为临时数组长度 // mergeLo:将len1 放入临时数组,mergeHi:将len2 放入临时数组 if (len1 <= len2) { mergeLo(base1, len1, base2, len2); } else { mergeHi(base1, len1, base2, len2); } }归并与Gollaping:
/** * 类似于mergeLo,除了这个方法应该只在len1 >= len2;如果len1 <= len2,则应该调用mergeLo。 * (两个方法都可以在len1 == len2时调用。) * * @param base1 Run1的队首元素 * @param len1 Run1的长度 * @param base2 Run2的队首元素(???must be aBase + aLen) * @param len2 Run2的长度 */ private void mergeHi(int base1, int len1, int base2, int len2) { assert len1 > 0 && len2 > 0 && base1 + len1 == base2; T[] a = this.a; // For performance T[] tmp = ensureCapacity(len2); int tmpBase = this.tmpBase; System.arraycopy(a, base2, tmp, tmpBase, len2); int cursor1 = base1 + len1 - 1; int cursor2 = tmpBase + len2 - 1; int dest = base2 + len2 - 1; // Move last element of first run and deal with degenerate cases a[dest--] = a[cursor1--]; if (--len1 == 0) { System.arraycopy(tmp, tmpBase, a, dest - (len2 - 1), len2); return; } // 简化操作,如果Run2要合并的元素只有一个,这个元素不比Run1的最大值大,也不比当前Run1索引的最小值大(base1的位置是大于Run2队首元素的位置),故Run2这个元素应该放置到Run1第一个 if (len2 == 1) { dest -= len1; // dest = dest - len1 (因前序dest已经-1,故是Run1队尾坐标),dest:Run1应该开始合并的起始位置:[....{1},6,16,0,27] cursor1 -= len1; // cursor1 = cursor1 - len1 (因前序cursor1已经-1,故是Run1倒数第二坐标),cursor1:dest的前序位置:[...{X},1,6,16,0,27] System.arraycopy(a, cursor1 + 1, a, dest + 1, len1); // [...{1,6,16},0,27] -> [...1,{1,6,16},27],将Run要排序部分后移一位 a[dest] = tmp[cursor2]; // [....1,1,6,16,27] -> [...0,1,6,16,27],将tmp中的唯一元素放置到队首 return; } Comparator<? super T> c = this.c; // Use local variable for performance int minGallop = this.minGallop; // " " " " " outer: while (true) { // 开始正常归并,并记录Run1、Run2 赢得选择的次数,如果大于minGallop则跳出进入GallopingMode int count1 = 0; // Number of times in a row that first run won int count2 = 0; // Number of times in a row that second run won /* * Do the straightforward thing until (if ever) one run * appears to win consistently. */ do { assert len1 > 0 && len2 > 1; if (c.compare(tmp[cursor2], a[cursor1]) < 0) { a[dest--] = a[cursor1--]; count1++; count2 = 0; if (--len1 == 0) { break outer; } } else { a[dest--] = tmp[cursor2--]; count2++; count1 = 0; if (--len2 == 1) { break outer; } } } while ((count1 | count2) < minGallop); /* * 一方已经连续合并超过minGallop次,则进入GallopingMode */ do { assert len1 > 0 && len2 > 1; count1 = len1 - gallopRight(tmp[cursor2], a, base1, len1, len1 - 1, c); if (count1 != 0) { dest -= count1; cursor1 -= count1; len1 -= count1; System.arraycopy(a, cursor1 + 1, a, dest + 1, count1); if (len1 == 0) { break outer; } } a[dest--] = tmp[cursor2--]; if (--len2 == 1) { break outer; } count2 = len2 - gallopLeft(a[cursor1], tmp, tmpBase, len2, len2 - 1, c); if (count2 != 0) { dest -= count2; cursor2 -= count2; len2 -= count2; System.arraycopy(tmp, cursor2 + 1, a, dest + 1, count2); if (len2 <= 1) { break outer; } } a[dest--] = a[cursor1--]; if (--len1 == 0) { break outer; } // 完成一次Galloping后对阈值做修改,并判断是否需要继续Galloping minGallop--; } while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP); if (minGallop < 0) { minGallop = 0; } minGallop += 2; // Penalize for leaving gallop mode } // End of "outer" loop this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field if (len2 == 1) { assert len1 > 0; dest -= len1; cursor1 -= len1; System.arraycopy(a, cursor1 + 1, a, dest + 1, len1); a[dest] = tmp[cursor2]; // Move first elt of run2 to front of merge } else if (len2 == 0) { throw new IllegalArgumentException("Comparison method violates its general contract!"); } else { assert len1 == 0; assert len2 > 0; System.arraycopy(tmp, tmpBase, a, dest - (len2 - 1), len2); } }Reference
原文转载:http://www.shaoqun.com/a/601592.html
勤商网:https://www.ikjzd.com/w/2219
vava:https://www.ikjzd.com/w/2780
本文基于JDK1.8.0_211撰写,基于java.util.Arrays.sort()方法浅谈目前Java所用到的排序算法,仅个人见解和笔记,若有问题欢迎指证,着重介绍其中的插入排序以及TimSort排序,其源于Python,并于JDK1.7引入Java以替代原有的归并排序。本文基于JDK1.8.0_211撰写,基于java.util.Arrays.sort()方法浅谈目前Java所用到的排序算
优1宝贝:https://www.ikjzd.com/w/1507
刘小东:https://www.ikjzd.com/w/1853
c-tick认证:https://www.ikjzd.com/w/2074
口述:同事把我两任男友都抢走(3/3):http://lady.shaoqun.com/m/a/40309.html
美国将于24日开征2000亿美元关税,中方将反征约600亿美元关税!:https://www.ikjzd.com/home/6995
通知:Shopee多站点政策有更新调整啦!:https://www.ikjzd.com/home/112315